Google ускорила Gemma 4 с помощью MTP drafters и пообещала до 3x прирост скорости
Google представила Multi-Token Prediction drafters для семейства Gemma 4. Компания заявляет, что новая схема speculative decoding даёт до 3x ускорение инференса без потери качества вывода и логики рассуждений.

Google выпустила Multi-Token Prediction drafters для Gemma 4 и делает ставку не на новую модель, а на ускорение уже существующей линейки. В компании утверждают, что новая архитектура speculative decoding позволяет заметно снизить задержки и получить до трёхкратного прироста скорости генерации без ухудшения качества ответов.
Главные тезисы
- Google выпустила Multi-Token Prediction drafters для семейства Gemma 4.
- Компания заявляет о приросте скорости инференса до 3x без потери качества вывода и логики рассуждений.
- В основе ускорения лежит speculative decoding со связкой тяжёлой основной модели и лёгкого drafter-модуля.
- Google объясняет, что обычный LLM inference часто упирается в memory bandwidth, а не в чистые вычисления.
- Прирост tokens-per-second тестировался на LiteRT-LM, MLX, Hugging Face Transformers и vLLM.
- Среди целевых сценариев названы coding assistants, автономные агенты и on-device мобильные приложения.
Google объявила о выпуске Multi-Token Prediction drafters для семейства Gemma 4. Анонс опубликован 5 мая 2026 года, а сама технология подаётся как способ ускорить инференс без изменения основной модели. В публикации Google прямо говорит, что Gemma 4 уже набрала более 60 миллионов загрузок за первые недели после запуска, а теперь компания пытается продвинуть линейку дальше за счёт повышения скорости отклика.
В основе обновления лежит speculative decoding. Google объясняет проблему так: стандартный инференс LLM упирается не столько в вычисления, сколько в memory bandwidth. Процессор тратит значительную часть времени на перенос миллиардов параметров из VRAM к вычислительным блокам, чтобы сгенерировать всего один токен. Из-за этого вычислительные ресурсы используются не полностью, а задержка остаётся высокой, особенно на потребительском железе.
Новая схема строится на связке тяжёлой основной модели и лёгкого drafter-модуля. Google приводит пример пары вроде Gemma 4 31B и MTP-модели, которая пытается заранее предсказать несколько следующих токенов за меньшее время, чем основной модели обычно требуется на обработку одного токена. Затем основная модель проверяет предложенную последовательность параллельно. Если предсказание совпадает, она принимает сразу весь фрагмент и вдобавок генерирует ещё один собственный токен в том же проходе.
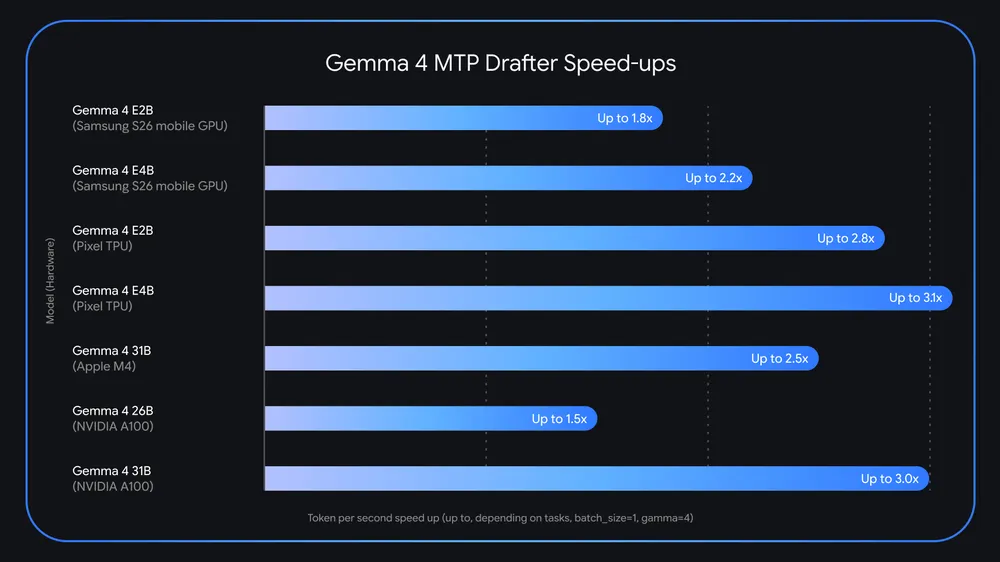
Именно на этом и строится обещанное ускорение. Google утверждает, что MTP drafters дают до 3x speedup без деградации output quality или reasoning logic. На странице отдельно сказано, что рост tokens-per-second тестировался на стеке LiteRT-LM, MLX, Hugging Face Transformers и vLLM. Это важно, потому что компания показывает не лабораторную схему в вакууме, а связку с реально используемыми инструментами инференса.
Отдельный акцент сделан на практических сценариях. В публикации перечислены coding assistants, автономные агенты с быстрым многошаговым планированием и мобильные приложения, которые работают полностью on-device. Во всех этих задачах скорость ответа часто ограничивает не возможности модели как таковой, а время отклика. Именно поэтому Google подаёт MTP как инфраструктурное улучшение для уже существующих рабочих сценариев, а не как академическую оптимизацию ради красивого графика.
Google также связывает релиз с локальной разработкой. Компания пишет, что при использовании Gemma 4 вместе с соответствующим drafter-модулем разработчики смогут быстрее запускать 26B MoE и 31B Dense модели на персональных компьютерах и потребительских GPU. Формулировка указывает на прямую ставку на edge и workstation-сценарии, где даже сильная модель бесполезна, если latency делает её неудобной в работе.
Технически это выглядит как попытка сдвинуть разговор о локальных open-моделях в сторону usability. До сих пор многие релизы обсуждались в первую очередь через качество модели, бенчмарки и размеры. Здесь основной тезис другой: если инфраструктурный bottleneck не решён, даже сильная модель остаётся медленной. Поэтому MTP drafters — это не “ещё одна модель рядом”, а способ сделать существующую Gemma 4 более пригодной для реального использования в IDE, агентных пайплайнах и on-device приложениях.