OpenAI Privacy Filter: Технический обзор архитектуры и интеграции в ML-пайплайны
Разбор модели OpenAI Privacy Filter: как из GPT-OSS сделали классификатор PII. Обзор архитектуры, интеграции в Python/JS и настройки операционной точки для баланса Precision/Recall.
В эпоху больших данных защита Personally Identifiable Information (PII) становится критической задачей для любых ML-систем. Модель OpenAI Privacy Filter предлагает решение для on-prem развертывания: это быстрая, контекстно-осознанная модель, способная обнаруживать и маскировать чувствительные данные в текстовых потоках.
OpenAI Privacy Filter: Технический обзор архитектуры и интеграции
Модель OpenAI Privacy Filter — это инструмент для обнаружения и маскирования PII (персонально идентифицируемой информации) в текстах. Она предназначена для высоконагруженных рабочих процессов по очистке данных, где командам требуется модель, которую можно запустить локально (on-premises), которая работает быстро, учитывает контекст и настраивается под конкретные задачи.
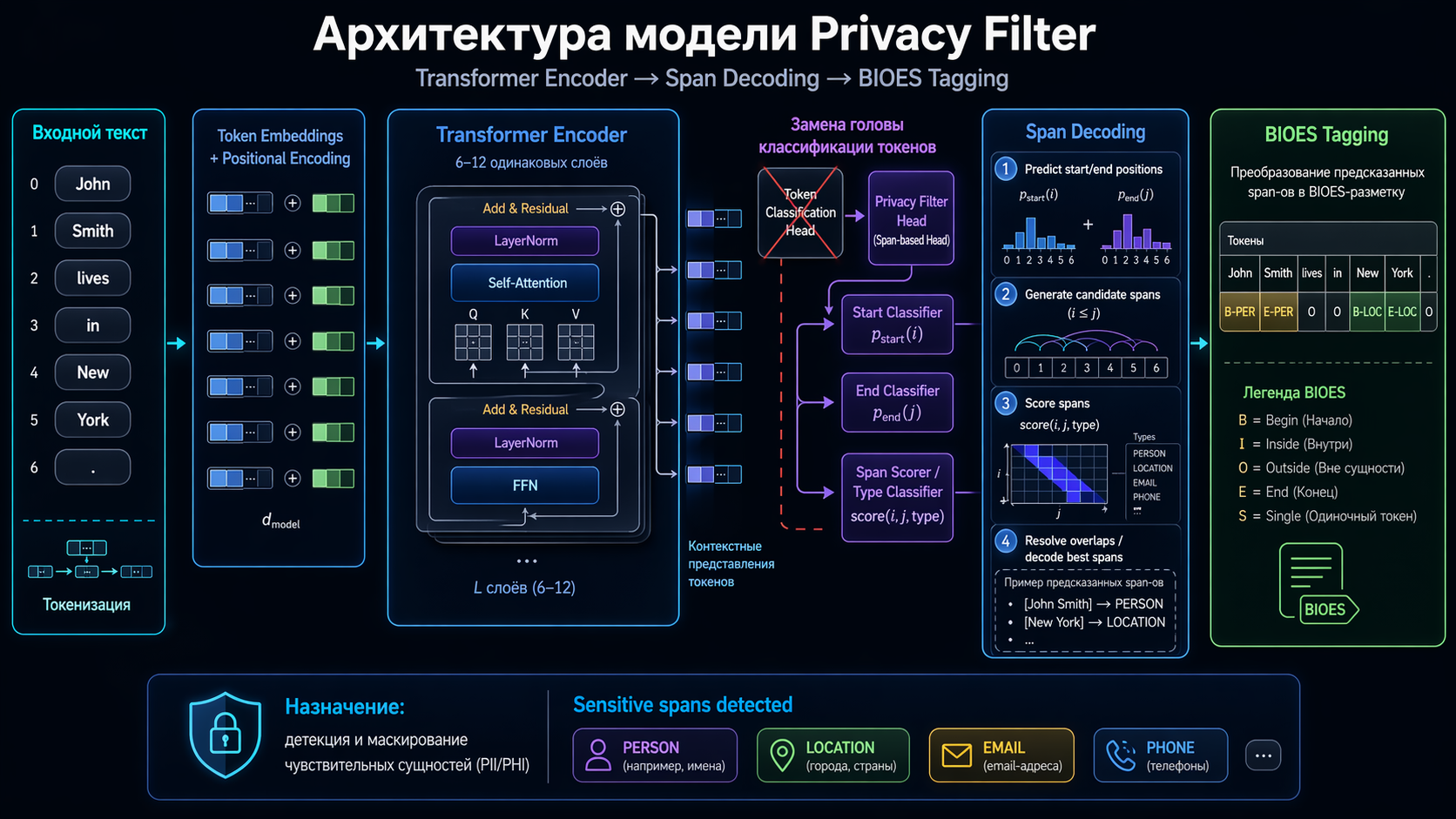
В отличие от генеративных моделей, которые создают текст посимвольно, Privacy Filter использует подход классификации токенов с последующим декодированием связных фрагментов (span decoding).
Архитектура: от GPT-OSS к классификатору
Модель была дообучена автогрессивно для получения контрольной точки, архитектура которой схожа с GPT-OSS, но меньшего размера. Затем эта контрольная точка была преобразована в бидирекционный (двусторонний) классификатор токенов над таксономией приватных меток.
Ключевые архитектурные особенности:
- Базовая модель: Автогрессивная предобученная контрольная точка.
- Замена головы модели (Head): Выходной слой для предсказания следующего токена заменен на голову классификации токенов над метками приватности.
- Post-training: Обучение проводится методом контролируемой классификации на уровне токенов, а не предсказания следующего токена.
- Decoding: Применяется ограничивающее последовательностное декодирование для получения связных BIOES-меток (Begin, Inside, Outside, End, Single).
Архитектурно реализация представляет собой стек пре-нормализованного трансформерского энкодера с:
- Токеновыми эмбеддингами.
- 8 повторными блоками трансформера.
- Группированным запросным вниманием (grouped-query attention) с rotary positional embeddings.
- Разреженными миксами экспертов (MoE) в feed-forward блоках (128 экспертов всего).
- Финальной головой классификации токенов над метками приватности (ширина потока остатков d_model = 640).
Ключевые преимущества и характеристики
| Характеристика | Описание |
|---|---|
| Лицензия | Apache 2.0 (идеально для экспериментов, кастомизации и коммерческого использования). |
| Размер | Всего 1.5B параметров (активных 50M), что позволяет запускать модель в браузере или на ноутбуке. |
| Контекст | Поддержка окна контекста до 128,000 токенов (обработка длинных текстов без разбиения). |
| Настройка | Возможность тонкой настройки точности/полноты через операционные точки (Operating Points). |
Классификация данных: 8 категорий PII
Модель может обнаруживать следующие категории приватных span:
- account_number (Номер счета)
- private_address (Частный адрес)
- private_email (Электронная почта)
- private_person (Человек/ФИО)
- private_phone (Телефон)
- private_url (URL)
- private_date (Дата)
- secret (Секрет/пароль)
Для классификации токенов каждая категория span расширяется до классов с границами: B-<label>, I-<label>, E-<label>, S-<label> плюс фоновый класс O. Всего модель предсказывает 33 класса на токен.
Практическое применение: интеграция в пайплайны
Интеграция через Python (Transformers)
Использование API pipeline для быстрой классификации:
from transformers import pipeline
classifier = pipeline(task="token-classification", model="openai/privacy-filter")
result = classifier("My name is Alice Smith")
print(result)
# Вывод: [{'entity_group': 'private_person', 'start': 10, 'end': 23, 'score': 0.99...}]Использование AutoModel для детального контроля:
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/privacy-filter")
model = AutoModelForTokenClassification.from_pretrained("openai/privacy-filter", device_map="auto")
inputs = tokenizer("My name is Alice Smith", return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model(**inputs)
predicted_token_class_ids = outputs.logits.argmax(dim=-1)
predicted_token_classes = [model.config.id2label[token_id.item()] for token_id in predicted_token_class_ids[0]]Интеграция через WebGPU (Transformers.js)
Модель можно запускать прямо в браузере:
import { pipeline } from "@huggingface/transformers";
const classifier = await pipeline("token-classification", "openai/privacy-filter", {
device: "webgpu",
dtype: "q4"
});
const input = "My name is Harry Potter and my email is harry.potter@hogwarts.edu.";
const output = await classifier(input, { aggregation_strategy: "simple" });
console.dir(output);
// Вывод: [{entity_group:'private_person', score:0.99..., word:' Harry Potter'}, ...]Настройка операционной точки (Operating Point)
После того как классификатор токенов производит logits на уровне каждого токена, метки декодируются с помощью ограниченного декодера Viterbi. Этот процесс использует линейную цепочку переходных оценок.
Механизм калибровки:
Декодер кодирует полные пути меток со стартом, переходами и концом, а также шестью параметрами смещения (bias), которые контролируют:
- Персистентность фона (background persistence).
- Вход в span (span entry).
- Продолжение span (span continuation).
- Закрытие span (span closure).
Операционная точка (Operating Point) позволяет настраивать баланс между точностью (Precision) и полнотой (Recall):
- Высокая полнота: Параметры поощряют вход в span и продолжение, что дает более широкие и непрерывные маски (лучше для recall).
- Высокая точность: Параметры поощряют пребывание в фоне, что снижает количество ложных срабатываний (лучше для precision).
В runtime пользователи могут настраивать эти параметры через предустановленные операционные точки.
Ограничения и риски: когда модель может ошибаться
Несмотря на эффективность, модель имеет ряд ограничений, о которых необходимо знать при внедрении:
1. Статичная политика меток (Static Label Policy)
Модель идентифицирует только те span, которые соответствуют обученной таксономии. Реальные сценарии использования разнообразны и сложны, а определения границ могут отличаться от дефолтных настроек модели. Для специфических корпоративных требований часто требуется калибровка или fine-tuning.
Важно: Модель не поддерживает динамическую настройку политик меток в runtime без fine-tuning. Изменение политик требует дообучения модели.
2. Производительность на non-English текстах
Хотя модель обучалась преимущественно на английском, производительность может снижаться на текстах на других языках, нелатинских скриптах или в доменах, отличающихся от обучающего распределения.
3. Сценарии провала (Failure Modes)
- False Negatives: Пропуск редких имен, региональных названий, инициалов или специфических идентификаторов доменов.
- False Positives: Избыточная маскировка публичных сущностей, организаций или общих существительных при неоднозначном контексте.
- Фрагментация границ: Проблемы со смешанным форматированием текста, длинными документами или тяжелыми пунктуационными артефактами.
- Пропуск секретов: Ошибки на новых форматах кредитов, специфических токенах проектов или секретах, разбитых синтаксисом.
4. Риск чрезмерной зависимости (Over-reliance)
Privacy Filter — это вспомогательный инструмент для редакции и минимизации данных, а не гарантия анонимизации или соответствия нормам. Чрезмерная зависимость от инструмента как от blanket-анонимизации может привести к пропуску целей приватности.
Рекомендации по внедрению
Для успешной интеграции в пайплайны обработки данных на Hugging Face рекомендуется:
- Privacy-by-Design: Используйте модель как часть комплексного подхода, а не как единственное средство анонимизации.
- Оценка до продакшена: Обязательно проводите оценку модели на локальных данных и с учетом внутренних политик перед развертыванием в production.
- Fine-tuning: Применяйте специфическое fine-tuning, если политика вашей организации отличается от базовых границ модели.
- Человеческий контроль: Сохраняйте пути для человеческого обзора (human review) в высокочувствительных рабочих процессах (медицина, юриспруденция, финансы).
Вывод
OpenAI Privacy Filter представляет собой мощный инструмент для обнаружения PII с архитектурой, оптимизированной для скорости и работы с длинным контекстом. Однако её использование требует понимания ограничений модели, особенно в части статичности политик меток и чувствительности к языку. Правильная настройка операционной точки и интеграция в многослойную стратегию безопасности обеспечат надежную защиту данных.